You are viewing documentation for an older version (0.8.1) of Kafka. For up-to-date documentation, see the latest version.
Basic Kafka Operations
Basic Kafka Operations
This section will review the most common operations you will perform on your Kafka cluster. All of the tools reviewed in this section are available under the bin/ directory of the Kafka distribution and each tool will print details on all possible commandline options if it is run with no arguments.
Adding and removing topics
You have the option of either adding topics manually or having them be created automatically when data is first published to a non-existent topic. If topics are auto-created then you may want to tune the default topic configurations used for auto-created topics.
Topics are added and modified using the topic tool:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --create --topic my_topic_name
--partitions 20 --replication-factor 3 --config x=y
The replication factor controls how many servers will replicate each message that is written. If you have a replication factor of 3 then up to 2 servers can fail before you will lose access to your data. We recommend you use a replication factor of 2 or 3 so that you can transparently bounce machines without interrupting data consumption.
The partition count controls how many logs the topic will be sharded into. There are several impacts of the partition count. First each partition must fit entirely on a single server. So if you have 20 partitions the full data set (and read and write load) will be handled by no more than 20 servers (no counting replicas). Finally the partition count impacts the maximum parallelism of your consumers. This is discussed in greater detail in the concepts section.
The configurations added on the command line override the default settings the server has for things like the length of time data should be retained. The complete set of per-topic configurations is documented here.
Modifying topics
You can change the configuration or partitioning of a topic using the same topic tool.
To add partitions you can do
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name
--partitions 40
Be aware that one use case for partitions is to semantically partition data, and adding partitions doesn’t change the partitioning of existing data so this may disturb consumers if they rely on that partition. That is if data is partitioned by hash(key) % number_of_partitions then this partitioning will potentially be shuffled by adding partitions but Kafka will not attempt to automatically redistribute data in any way.
To add configs:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --config x=y
To remove a config:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic my_topic_name --deleteConfig x
And finally deleting a topic:
> bin/kafka-topics.sh --zookeeper zk_host:port/chroot --delete --topic my_topic_name
WARNING: Delete topic functionality is beta in 0.8.1. Please report any bugs that you encounter on the mailing list or JIRA.
Kafka does not currently support reducing the number of partitions for a topic or changing the replication factor.
Graceful shutdown
The Kafka cluster will automatically detect any broker shutdown or failure and elect new leaders for the partitions on that machine. This will occur whether a server fails or it is brought down intentionally for maintenance or configuration changes. For the later cases Kafka supports a more graceful mechanism for stoping a server then just killing it. When a server is stopped gracefully it has two optimizations it will take advantage of:
It will sync all its logs to disk to avoid needing to do any log recovery when it restarts (i.e. validating the checksum for all messages in the tail of the log). Log recovery takes time so this speeds up intentional restarts.
It will migrate any partitions the server is the leader for to other replicas prior to shutting down. This will make the leadership transfer faster and minimize the time each partition is unavailable to a few milliseconds. Syncing the logs will happen automatically happen whenever the server is stopped other than by a hard kill, but the controlled leadership migration requires using a special setting:
controlled.shutdown.enable=true
Note that controlled shutdown will only succeed if all the partitions hosted on the broker have replicas (i.e. the replication factor is greater than 1 and at least one of these replicas is alive). This is generally what you want since shutting down the last replica would make that topic partition unavailable.
Balancing leadership
Whenever a broker stops or crashes leadership for that broker’s partitions transfers to other replicas. This means that by default when the broker is restarted it will only be a follower for all its partitions, meaning it will not be used for client reads and writes.
To avoid this imbalance, Kafka has a notion of preferred replicas. If the list of replicas for a partition is 1,5,9 then node 1 is preferred as the leader to either node 5 or 9 because it is earlier in the replica list. You can have the Kafka cluster try to restore leadership to the restored replicas by running the command:
> bin/kafka-preferred-replica-election.sh --zookeeper zk_host:port/chroot
Since running this command can be tedious you can also configure Kafka to do this automatically by setting the following configuration:
auto.leader.rebalance.enable=true
Mirroring data between clusters
We refer to the process of replicating data between Kafka clusters “mirroring” to avoid confusion with the replication that happens amongst the nodes in a single cluster. Kafka comes with a tool for mirroring data between Kafka clusters. The tool reads from one or more source clusters and writes to a destination cluster, like this:
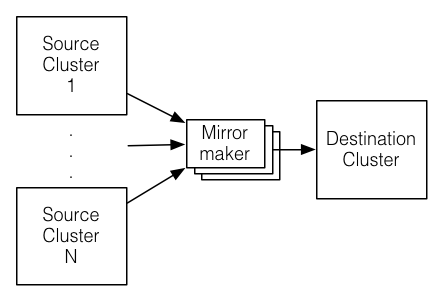
A common use case for this kind of mirroring is to provide a replica in another datacenter. This scenario will be discussed in more detail in the next section.
You can run many such mirroring processes to increase throughput and for fault-tolerance (if one process dies, the others will take overs the additional load).
Data will be read from topics in the source cluster and written to a topic with the same name in the destination cluster. In fact the mirror maker is little more than a Kafka consumer and producer hooked together.
The source and destination clusters are completely independent entities: they can have different numbers of partitions and the offsets will not be the same. For this reason the mirror cluster is not really intended as a fault-tolerance mechanism (as the consumer position will be different); for that we recommend using normal in-cluster replication. The mirror maker process will, however, retain and use the message key for partitioning so order is preserved on a per-key basis.
Here is an example showing how to mirror a single topic (named my-topic) from two input clusters:
> bin/kafka-run-class.sh kafka.tools.MirrorMaker
--consumer.config consumer-1.properties --consumer.config consumer-2.properties
--producer.config producer.properties --whitelist my-topic
Note that we specify the list of topics with the --whitelist option. This option allows any regular expression using Java-style regular expressions. So you could mirror two topics named A and B using --whitelist 'A|B'. Or you could mirror all topics using --whitelist '*'. Make sure to quote any regular expression to ensure the shell doesn’t try to expand it as a file path. For convenience we allow the use of ‘,’ instead of ‘|’ to specify a list of topics.
Sometime it is easier to say what it is that you don’t want. Instead of using --whitelist to say what you want to mirror you can use --blacklist to say what to exclude. This also takes a regular expression argument.
Combining mirroring with the configuration auto.create.topics.enable=true makes it possible to have a replica cluster that will automatically create and replicate all data in a source cluster even as new topics are added.
Checking consumer position
Sometimes it’s useful to see the position of your consumers. We have a tool that will show the position of all consumers in a consumer group as well as how far behind the end of the log they are. To run this tool on a consumer group named my-group consuming a topic named my-topic would look like this:
> bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zkconnect localhost:2181 --group test
Group Topic Pid Offset logSize Lag Owner
my-group my-topic 0 0 0 0 test_jkreps-mn-1394154511599-60744496-0
my-group my-topic 1 0 0 0 test_jkreps-mn-1394154521217-1a0be913-0
Expanding your cluster
Adding servers to a Kafka cluster is easy, just assign them a unique broker id and start up Kafka on your new servers. However these new servers will not automatically be assigned any data partitions, so unless partitions are moved to them they won’t be doing any work until new topics are created. So usually when you add machines to your cluster you will want to migrate some existing data to these machines.
The process of migrating data is manually initiated but fully automated. Under the covers what happens is that Kafka will add the new server as a follower of the partition it is migrating and allow it to fully replicate the existing data in that partition. When the new server has fully replicated the contents of this partition and joined the in-sync replica one of the existing replicas will delete their partition’s data.
The partition reassignment tool can be used to move partitions across brokers. An ideal partition distribution would ensure even data load and partition sizes across all brokers. In 0.8.1, the partition reassignment tool does not have the capability to automatically study the data distribution in a Kafka cluster and move partitions around to attain an even load distribution. As such, the admin has to figure out which topics or partitions should be moved around.
The partition reassignment tool can run in 3 mutually exclusive modes -
- --generate: In this mode, given a list of topics and a list of brokers, the tool generates a candidate reassignment to move all partitions of the specified topics to the new brokers. This option merely provides a convenient way to generate a partition reassignment plan given a list of topics and target brokers.
- --execute: In this mode, the tool kicks off the reassignment of partitions based on the user provided reassignment plan. (using the –reassignment-json-file option). This can either be a custom reassignment plan hand crafted by the admin or provided by using the –generate option
- --verify: In this mode, the tool verifies the status of the reassignment for all partitions listed during the last –execute. The status can be either of successfully completed, failed or in progress
Automatically migrating data to new machines
The partition reassignment tool can be used to move some topics off of the current set of brokers to the newly added brokers. This is typically useful while expanding an existing cluster since it is easier to move entire topics to the new set of brokers, than moving one partition at a time. When used to do this, the user should provide a list of topics that should be moved to the new set of brokers and a target list of new brokers. The tool then evenly distributes all partitions for the given list of topics across the new set of brokers. During this move, the replication factor of the topic is kept constant. Effectively the replicas for all partitions for the input list of topics are moved from the old set of brokers to the newly added brokers.
For instance, the following example will move all partitions for topics foo1,foo2 to the new set of brokers 5,6. At the end of this move, all partitions for topics foo1 and foo2 will only exist on brokers 5,6
Since, the tool accepts the input list of topics as a json file, you first need to identify the topics you want to move and create the json file as follows-
> cat topics-to-move.json
{"topics": [{"topic": "foo1"},
{"topic": "foo2"}],
"version":1
}
Once the json file is ready, use the partition reassignment tool to generate a candidate assignment-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generate
Current partition replica assignment
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},
{"topic":"foo1","partition":0,"replicas":[3,4]},
{"topic":"foo2","partition":2,"replicas":[1,2]},
{"topic":"foo2","partition":0,"replicas":[3,4]},
{"topic":"foo1","partition":1,"replicas":[2,3]},
{"topic":"foo2","partition":1,"replicas":[2,3]}]
}
Proposed partition reassignment configuration
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},
{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":2,"replicas":[5,6]},
{"topic":"foo2","partition":0,"replicas":[5,6]},
{"topic":"foo1","partition":1,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[5,6]}]
}
The tool generates a candidate assignment that will move all partitions from topics foo1,foo2 to brokers 5,6. Note, however, that at this point, the partition movement has not started, it merely tells you the current assignment and the proposed new assignment. The current assignment should be saved in case you want to rollback to it. The new assignment should be saved in a json file (e.g. expand-cluster-reassignment.json) to be input to the tool with the –execute option as follows-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
Current partition replica assignment
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[1,2]},
{"topic":"foo1","partition":0,"replicas":[3,4]},
{"topic":"foo2","partition":2,"replicas":[1,2]},
{"topic":"foo2","partition":0,"replicas":[3,4]},
{"topic":"foo1","partition":1,"replicas":[2,3]},
{"topic":"foo2","partition":1,"replicas":[2,3]}]
}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions
{"version":1,
"partitions":[{"topic":"foo1","partition":2,"replicas":[5,6]},
{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":2,"replicas":[5,6]},
{"topic":"foo2","partition":0,"replicas":[5,6]},
{"topic":"foo1","partition":1,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[5,6]}]
}
Finally, the –verify option can be used with the tool to check the status of the partition reassignment. Note that the same expand-cluster-reassignment.json (used with the –execute option) should be used with the –verify option
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
Status of partition reassignment:
Reassignment of partition [foo1,0] completed successfully
Reassignment of partition [foo1,1] is in progress
Reassignment of partition [foo1,2] is in progress
Reassignment of partition [foo2,0] completed successfully
Reassignment of partition [foo2,1] completed successfully
Reassignment of partition [foo2,2] completed successfully
Custom partition assignment and migration
The partition reassignment tool can also be used to selectively move replicas of a partition to a specific set of brokers. When used in this manner, it is assumed that the user knows the reassignment plan and does not require the tool to generate a candidate reassignment, effectively skipping the –generate step and moving straight to the –execute step
For instance, the following example moves partition 0 of topic foo1 to brokers 5,6 and partition 1 of topic foo2 to brokers 2,3
The first step is to hand craft the custom reassignment plan in a json file-
> cat custom-reassignment.json
{"version":1,"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}
Then, use the json file with the –execute option to start the reassignment process-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file custom-reassignment.json --execute
Current partition replica assignment
{"version":1,
"partitions":[{"topic":"foo1","partition":0,"replicas":[1,2]},
{"topic":"foo2","partition":1,"replicas":[3,4]}]
}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions
{"version":1,
"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},
{"topic":"foo2","partition":1,"replicas":[2,3]}]
}
The –verify option can be used with the tool to check the status of the partition reassignment. Note that the same expand-cluster-reassignment.json (used with the –execute option) should be used with the –verify option
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file custom-reassignment.json --verify
Status of partition reassignment:
Reassignment of partition [foo1,0] completed successfully
Reassignment of partition [foo2,1] completed successfully
Decommissioning brokers
The partition reassignment tool does not have the ability to automatically generate a reassignment plan for decommissioning brokers yet. As such, the admin has to come up with a reassignment plan to move the replica for all partitions hosted on the broker to be decommissioned, to the rest of the brokers. This can be relatively tedious as the reassignment needs to ensure that all the replicas are not moved from the decommissioned broker to only one other broker. To make this process effortless, we plan to add tooling support for decommissioning brokers in 0.8.2.
Increasing replication factor
Increasing the replication factor of an existing partition is easy. Just specify the extra replicas in the custom reassignment json file and use it with the –execute option to increase the replication factor of the specified partitions.
For instance, the following example increases the replication factor of partition 0 of topic foo from 1 to 3. Before increasing the replication factor, the partition’s only replica existed on broker 5. As part of increasing the replication factor, we will add more replicas on brokers 6 and 7.
The first step is to hand craft the custom reassignment plan in a json file-
> cat increase-replication-factor.json
{"version":1,
"partitions":[{"topic":"foo","partition":0,"replicas":[5,6,7]}]}
Then, use the json file with the –execute option to start the reassignment process-
> bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,
"partitions":[{"topic":"foo","partition":0,"replicas":[5]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started reassignment of partitions
{"version":1,
"partitions":[{"topic":"foo","partition":0,"replicas":[5,6,7]}]}
The –verify option can be used with the tool to check the status of the partition reassignment. Note that the same increase-replication-factor.json (used with the –execute option) should be used with the –verify option
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition [foo,0] completed successfully
You can also verify the increase in replication factor with the kafka-topics tool-
> bin/kafka-topics.sh --zookeeper localhost:2181 --topic foo --describe
Topic:foo PartitionCount:1 ReplicationFactor:3 Configs:
Topic: foo Partition: 0 Leader: 5 Replicas: 5,6,7 Isr: 5,6,7
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.